I Spent Three Months Turning My Brain into an API
Every PKM tool I've used failed for the same reason — they solved storage, not cognition. Here's what I built instead.
The most important sentence first: every PKM tool I’ve used failed for the same reason — they solved storage, not cognition. Those are different problems with completely different solutions.
The Graveyard
I’ve used Notion, Obsidian, Roam, Logseq. Every one died the same death:
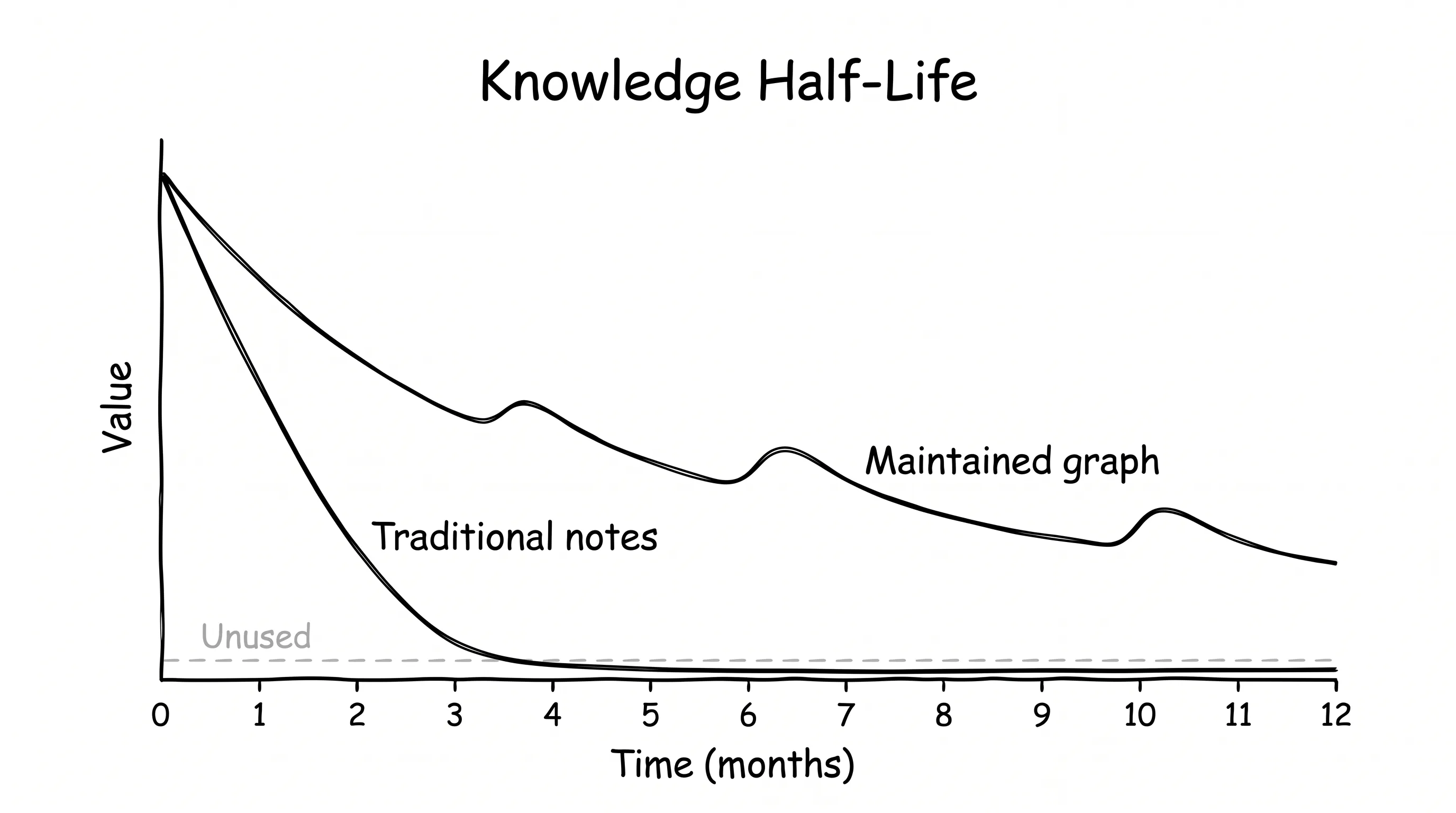
Enthusiasm → Maintenance → Forgetting → Ruins.
The ruins look like this: I’d rather open a new file than search my old notes. Because even when I find them, I can’t trust them. AI landscape notes from 2023? Half obsolete. The half that still matters? Context is gone.
I thought this was a discipline problem. It isn’t. It’s a structural problem with how these tools model knowledge: as data to be stored, not cognition to be maintained.
The Moment
Late 2025. I’m using Claude Code to work through a complex product decision. It digs through my files, finds an analysis I’d written few months earlier, and references a conclusion I’d completely forgotten making.
I sat with that for a second.
Then I realized: if an AI agent can read and write my local files in real time, my notes can have a runtime. They’re not just things that sit there. They can be queried, reasoned over, updated, composed — like a codebase.
This reframes the whole problem. I didn’t need a better note-taking app. I needed a knowledge structure that an AI could actually operate on.
What It Is
Some friends recommended ITO Engine (Input-Think-Output). The core is a graph database in JSON-LD format.
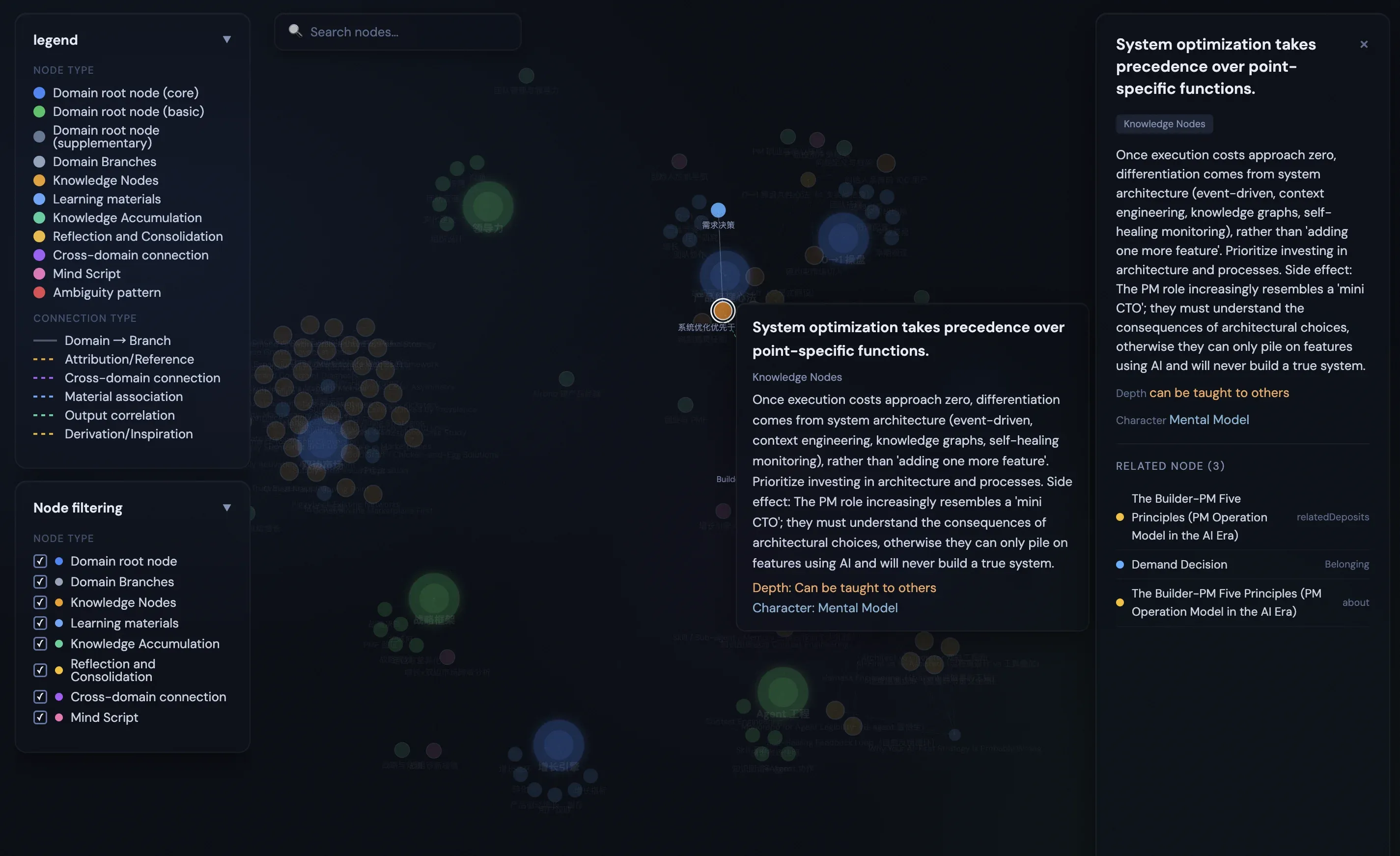
JSON-LD sounds technical. The idea is simple: every piece of knowledge has an ID, and IDs can have named connections to other IDs. “Marketplace cold start” connects to “MVP thinking” via an edge that says “same underlying logic, two domains.” That edge is the insight — not the nodes.
The graph stores more than “what is X.” It stores:
- My relationship with X: when I first encountered it, how many times, what my actual take is
- When I’ve applied this concept in a real decision (
appliedInlog) - Cross-domain connections to other clusters of knowledge
The third one matters most. I’ll come back to it.
Getting Knowledge In
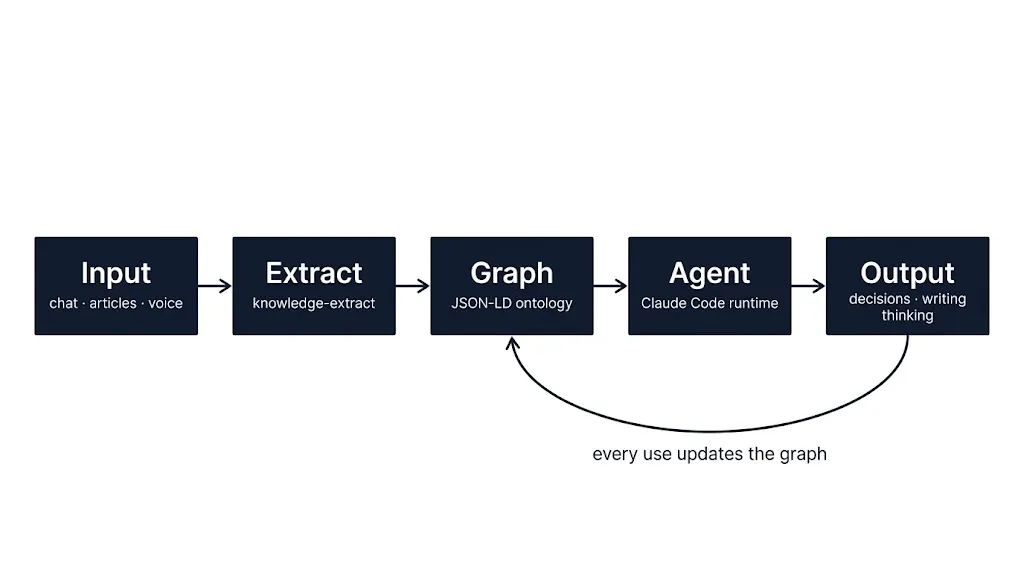
Conversation as capture. /chat opens a Socratic dialogue mode. When it ends, the system extracts knowledge nodes, updates the graph, archives the full transcript. It’s not recording “I know X” — it’s capturing “here’s how I actually think about X.”
Read something good, pipe it in. /pass-note takes articles, podcast segments, tweets. The system identifies what’s new, what’s redundant, what connects to existing nodes. Only actual incremental knowledge enters the graph.
Made a decision, note it. /write-note takes stream-of-thought. “Decided not to build X because…” becomes: a decision record + an appliedIn log update on the relevant mental model + a cognitive trajectory entry for the week. Three minutes.
Why It Doesn’t Rot
Traditional notes rot because maintenance requires willpower. Willpower runs out.
ITO system uses decay detection: every node has a lastContact timestamp. Anything untouched for 90 days gets flagged for the next weekly review — archive it, delete it, or find a reason to re-engage.
Same principle as purging dead code from a codebase. You don’t wait until it causes a bug. You make staleness visible, then act.
The graph grows but doesn’t bloat. Every active node is one I’ve actually interacted with recently.
Using It
For decisions: /brain mode (read-only, no writes) pulls relevant frameworks from the graph, checks their appliedIn history, and gives me a cognitive projection — not a generic LLM answer, but my frameworks applied to my problem. There’s a real difference.
For structured thinking: The graph has compiled “thinking scripts” — scenario-specific thinking steps assembled from my own knowledge nodes. For a growth-meets-marketplace problem, the script walks me through: constraint focus → trust building → cold start → pricing strategy → flywheel validation. Not a template. My own thinking patterns, frozen and repeatable.
For writing: Pull everything in a domain tagged with high outputPotential. Each node has my personal insight and applied examples. Writing becomes reorganizing what I’ve already thought — not re-researching from scratch.
The Thing That Actually Matters
I figure the value of this system is how much knowledge it has stored.
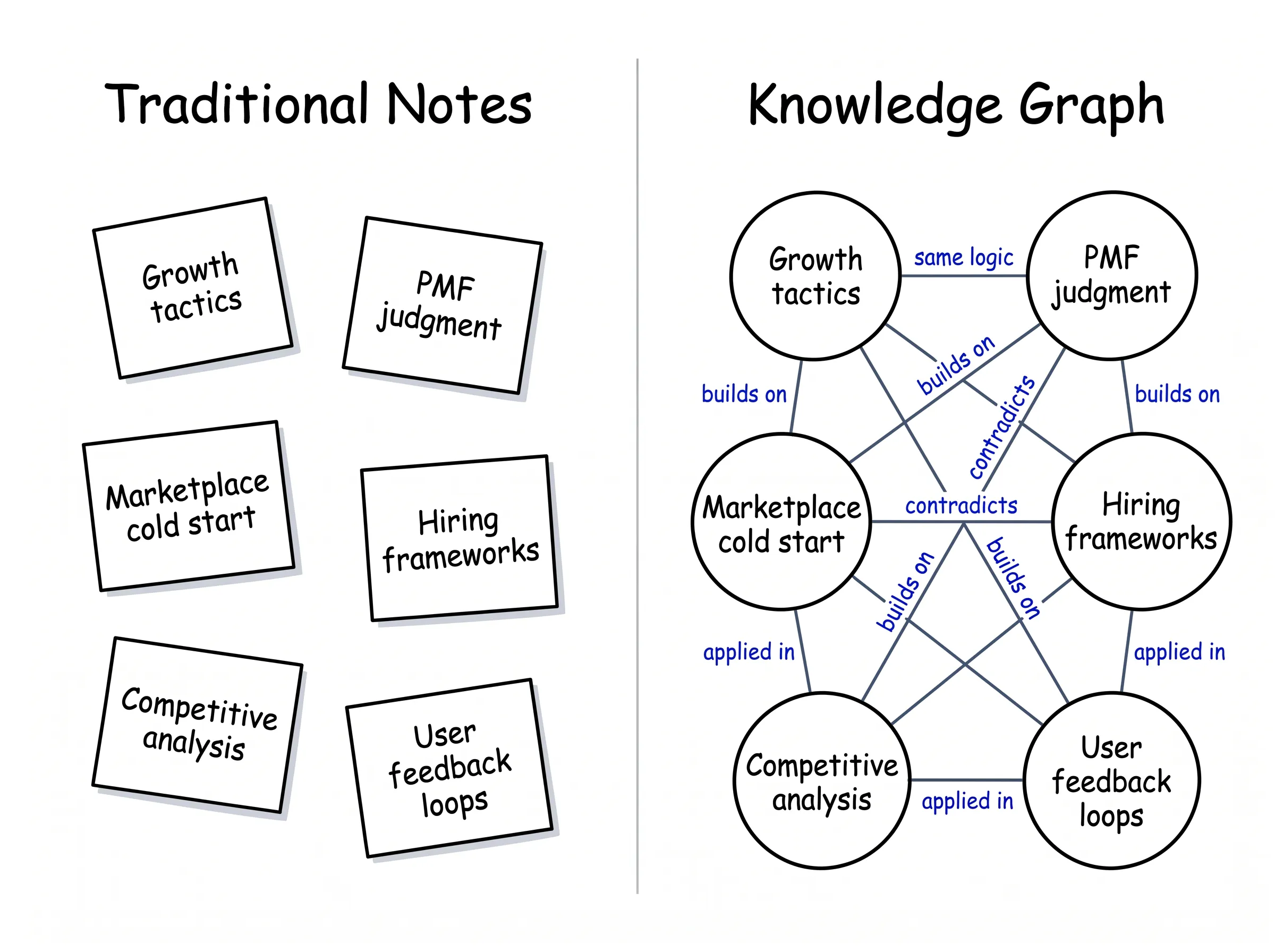
It isn’t. The value is in the edges.
When I discovered that the “focus principle” from growth strategy and “constrain-first” from marketplace mechanics are the same underlying logic in two domains — that moment was worth more than a hundred articles.
That kind of connection is only visible when two clusters of knowledge exist in the same traversable structure. In a flat list of notes, you’d never connect a marketplace supply piece to something you wrote eight months ago about PMF judgment. In a graph, connections are first-class objects.
This is what conventional PKM tools fundamentally miss. They’re optimizing for recall. A graph optimizes for inference.
What I Haven’t Solved
Bootstrap cost. Getting to a functional graph takes few hours of initial input. There’s a bulk import flow, but the bar is real.
ROI is unmeasurable. I can’t point to “the graph saved me two hours today.” The payoff is compounding and diffuse — like snowboarding or tennis. You don’t know which workout made you stronger. You know stopping makes you weaker.
Runtime dependency. The system runs on Claude Code. My files are mine, my structure is mine, but the agent isn’t. If Anthropic changes pricing or the API, I rewrite the runtime layer. I’ve accepted this risk. Worth naming it.
Open Source
ITO Engine is open source under AGPL-3.0.github.com/froleaf/ito-engine
AGPL wasn’t a casual pick. It requires any modified version — including one offered as a network service — to also stay open. The author want this to stay in the commons, not get forked into a product and closed off.
If you’re a builder who’s annoyed at notes that rot, an engineer who wants persistent memory across Claude Code sessions, or a researcher curious about knowledge graphs + agents — the repo is open.
Issues, forks, and direct conversations all welcome.
Why Now
This wasn’t possible in 2023. There were no AI agents that could read and write local files in real time. The knowledge could live on disk — no agent could operate on it interactively.
That changed. And when the runtime became available, the question became: what’s the right structure for the knowledge?
Not flat files. Not a folder of markdown. A graph.